
History likes to repeat itself, and after the first battle usually comes the second. So here we are, running the sequel to the Great LLM Translation War released in 2025.
Since then, the AI models have improved significantly, new players have emerged, some have lost their popularity, and some have gained a bit more. But the number of users and output quality are not the only metrics that shifted.
The way people interact with LLMs has fundamentally changed: from single prompts fired into a chat window to structured workflows built around context, consistency, and control.
In 2025, you picked a model and prompted it. In 2026, you create translation workflows built around context, consistency, and quality control. This includes AI in-context tools in Translation Management Systems that refine QA, style, and terminology consistency, and vibe-coded solutions with an LLM layer designed to meet the burning business needs.
The popularity of context-infusing features such as AI Projects or custom assistants offered by some LLMs has grown, too, which is reflected in OpenAI's State of Enterprise AI report, published in December 2025. It indicates that usage of structured workflows such as Projects and Custom GPTs increased 19× year-to-date, now accounting for 20% of all enterprise messages.
In 2025, you picked a model and prompted it. In 2026, you create translation workflows built around context, consistency, and quality control
Databricks’ 2026 State of AI Agents report paints a similar picture: enterprises are moving from single chatbots to multi-agent workflows, which grew 327% in less than four months. This shows a rapid shift toward more complex agentic systems rather than single-turn chat use.
Add to it easy set-up for connection with external apps, quick access to tools covering your most common tasks (e.g., with Claude Agent Skills), and options to work with files on your desktop (e.g., with Claude Cowork), and you’ll gain endless possibilities of customization and context enhancement, leading to better quality. And this quality is sometimes as good as human translation.
But don’t take my word for it.
👀 Well configured model > "best" model 🔗
The findings of the WMT25 General Machine Translation Shared Task run across 30 language pairs on challenging texts from six different domains and three source languages indicate that Gemini 2.5 Pro deserves the highest place on the podium. It was the top performer for 14 language pairs, and the translation quality generated by this model was equal to or better than human translation in 10 of those pairs.
What’s more, human translations, often considered the “gold standard,” ended up in the top cluster for only six of the 15 language pairs. These results could reflect the stylistic or lexical preferences of annotators, but one thing is sure: when properly set up and equipped with the right context, AI models can now deliver surprisingly accurate output.
The best-performing models now are the best configured, the most context-aware, and the most consistent ones
Similar observations can be found in the State of Translation Automation 2025 Industry Report by Intento. Its data shows that tailored solutions consistently beat generic engines. What’s more, human reviewers frequently couldn't tell AI output apart from human translation and often preferred the text created by AI. Instead of naming a single best-performing model, the report indicates that the best scenario is to use a multi-agent workflow. With separate agents for translation, review, and post-editing, this solution produced the highest average performance, earning the top ratings in 9 of 11 language pairs.
The results vary per language pair (e.g., Claude Opus 4 and Sonnet 3.7 ranked the best for German, Japanese, Korean, and Italian, while Gemini 2.5 Pro and Flash were the best for Chinese, Ukrainian, and French), but the key message to take home is: the model choice matters less than how you configure it. This confirms the prevailing assumption that once fueled by the right context, your AI model can be unstoppable.
🤺 The battle rules explained 🔗
Considering how fast things are changing, a follow-up to the Great LLM Translation War seems like a must. So, I’ve risen to the challenge and divided the world into two parts again: East and West, and assigned three models to each side.
The East Side is represented by Kimi K2, DeepSeek, and Qwen, whereas the West Side is all about ChatGPT, Claude, and Gemini.
Why these models? 🔗
The battle participants were partially selected by popularity scores (the West Side models), partially by curiosity (Kimi K2, the newest of them all), and partially to allow for handy comparison with the first battle, where DeepSeek and Qwen gained surprisingly good results.
What are we testing? 🔗
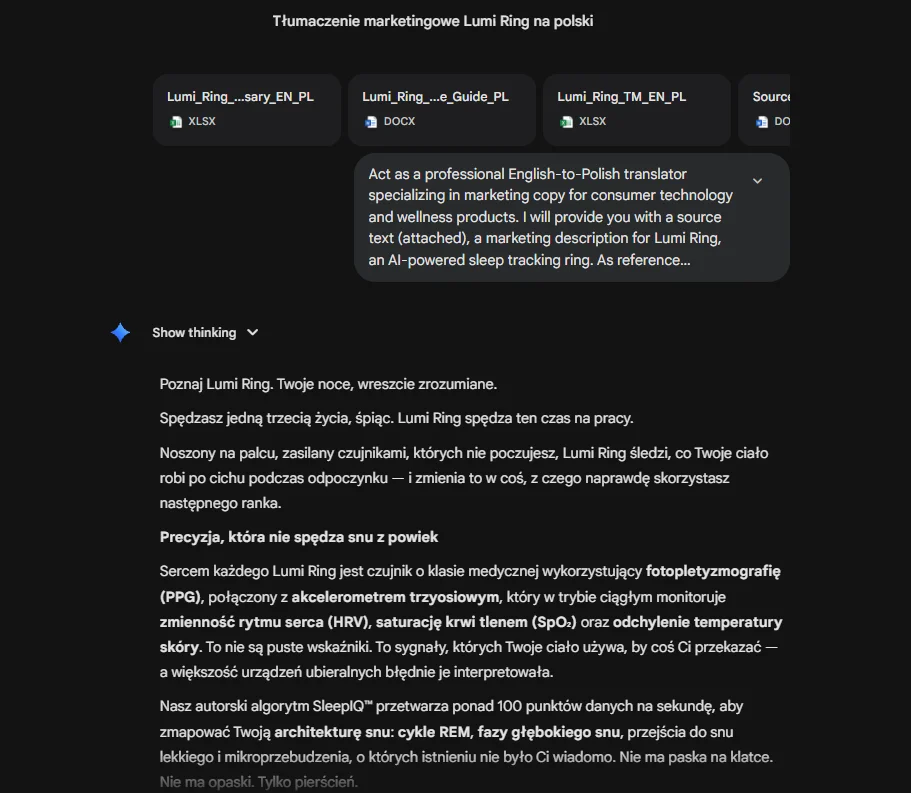
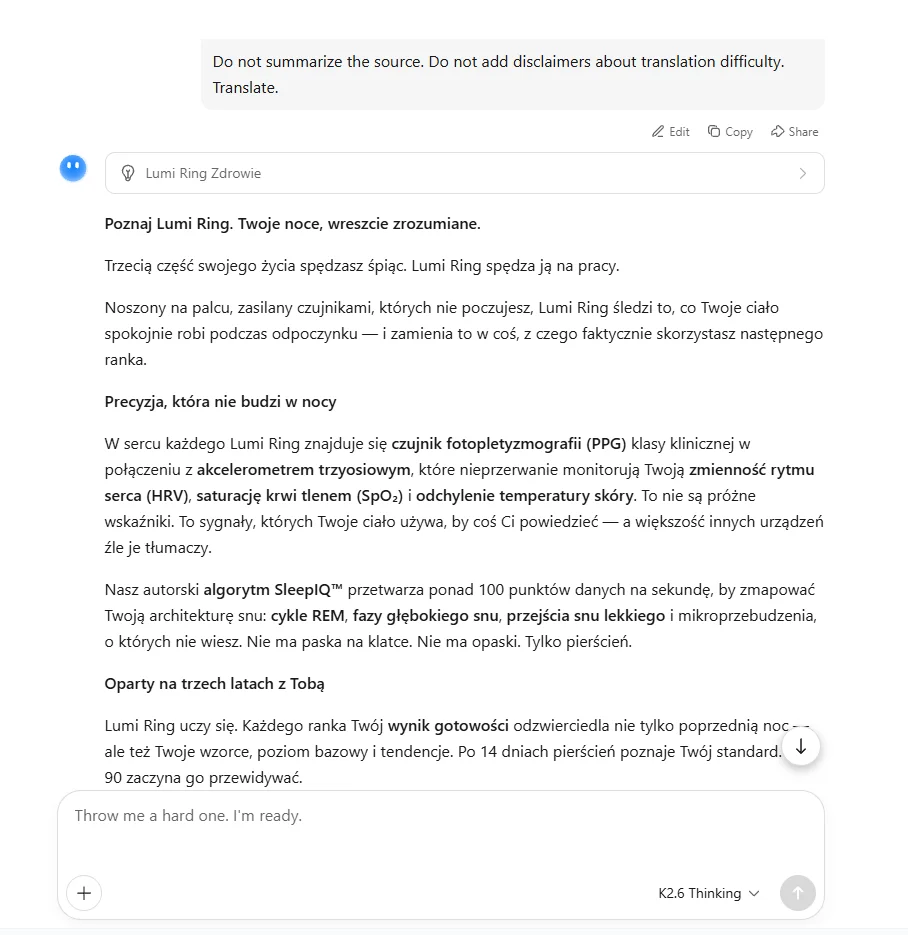
📄 The full text provided for each model is more complex than in battle no. 1; it’s also longer, comprising 450 words of marketing copy about a fictional AI-powered sleep-tracking ring. The source is English and requires strict adherence to reference materials to be rendered correctly. That’s why every model will receive not only the source, but also the relevant context.
💬 Where possible, all these assets will be fed into a project built inside the model – no integrations with TMS or other platforms, just a standard setup on the LLM website with reference files attached to the prompt. This makes the battle fair for everyone (not all tested LLMs can be integrated with localization platforms), and you, my dear reader, can easily replicate the results without worrying about any missing technology or connections.
For a better taste of the source, here’s a sample of our imaginary product:
What about assessment? 🔗
To allow for a direct comparison, the scoring criteria will remain the same. Output from every model will be assessed by professional translators based on:
1️⃣ Consistency with translation memories
2️⃣ Coherence across paragraphs
3️⃣ Consistency with the style guide (e.g., gender neutral, engaging)
4️⃣ Contextual appropriateness (e.g., does it fit the marketing context? Is it right for the target users?)
5️⃣ Accuracy (how closely the translated text matches the meaning of the source text)
6️⃣ Fluency (whether the translated text reads naturally in the target language)
All these indicators will be assessed on a scale from 1 to 5 for two language pairs covered in the Battle no. 1: 🇵🇱 English-Polish, a medium-source language, and 🇭🇷 English-Croatian, a low-resource language. A note on the last indicator: it replaces the “Correct rendering of mobile app strings” from the previous test, since now the translated content will differ.
✍️ This time, the source text won’t contain mobile app strings, but something more challenging: marketing copy for a technical product. Packed with brand voice, technical terms, and references to other campaigns. Something where literal translation is a big no-no, style guide matters, and consistency with previously released content is crucial.
📓 Each LLM will be asked to provide a context-specific translation, based on a detailed style guide (including, e.g., friendly, approachable style, gender-neutral language, correct terminology, non-translatable terms), glossary (10 terms in English with Polish and Croatian translations), and translation memory uploaded as an XLSX file (30 segments of varied match rate, from 100% to 50%). The instructions will also contain information about the type of results we’re looking for, such as natural, engaging translation consistent with the uploaded documents.
🧠 For each LLM, we’ll choose the currently newest version, preferably with the thinking capability, since analyzing so many references requires a deeper understanding.
💬 Finally, each model will be presented with the same prompt:
Disclaimer: The translation quality assessments and comparisons presented in this article are based on a limited set of tests performed by language professionals and should not be considered exhaustive or definitive. Due to constraints such as access to full model capabilities, proprietary algorithms, and the broad range of potential test conditions, our benchmarking efforts may not fully capture the capabilities of each model. We encourage readers to consult additional research and papers that offer more extensive benchmarking analyses. Bear in mind also that models used in these tests are updated and change all the time. Our benchmarking criteria might be limited.
⚔️ The great LLM battle no. 2 🔗
Below you can see the result of our great translation battle, categorized by models. First come the three Western LLMs, followed by the Eastern group.
ChatGPT, version GPT-5.5, standard thinking 🔗
For this and the following model, translations were set up as Projects. In Polish, all glossary terms landed correctly, and the style guide was applied. On the TM side, the model tried to make an effort, but it was quite selective. For 95% matches, it often reached for its own phrasing instead, for example, it translated “while you rest” as "gdy odpoczywasz" rather than "podczas odpoczynku" available in the TM.
It made similar blunders for "dane z czujników" instead of "dane czujnikowe" (“sensor data”) or "metryki próżności" instead of "wskaźniki próżności" (“vanity metrics”) that were expected based on the TM. Most 85% matches were missed entirely. There were three 100% matches available; the model applied two of them and rewrote the third from scratch. And that was the opening sentence – so not something hidden in the middle that could be difficult to recognize.
It seems ChatGPT trusted itself more than the abundant TM. The translation was accurate, but not entirely fluent, with many awkward or slightly literal phrases.
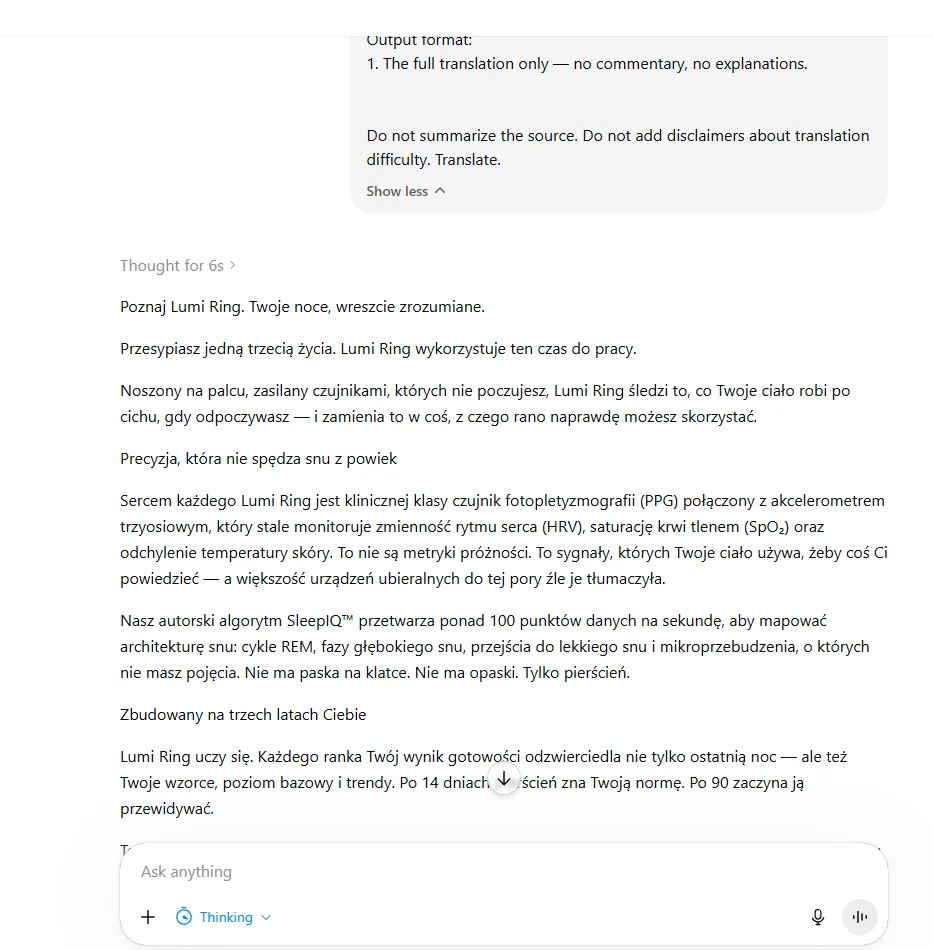
In Croatian, this model provided the most balanced output overall. It ranked high in every single category, and the output required only minor post-editing, mainly for a few slightly literal formulations.
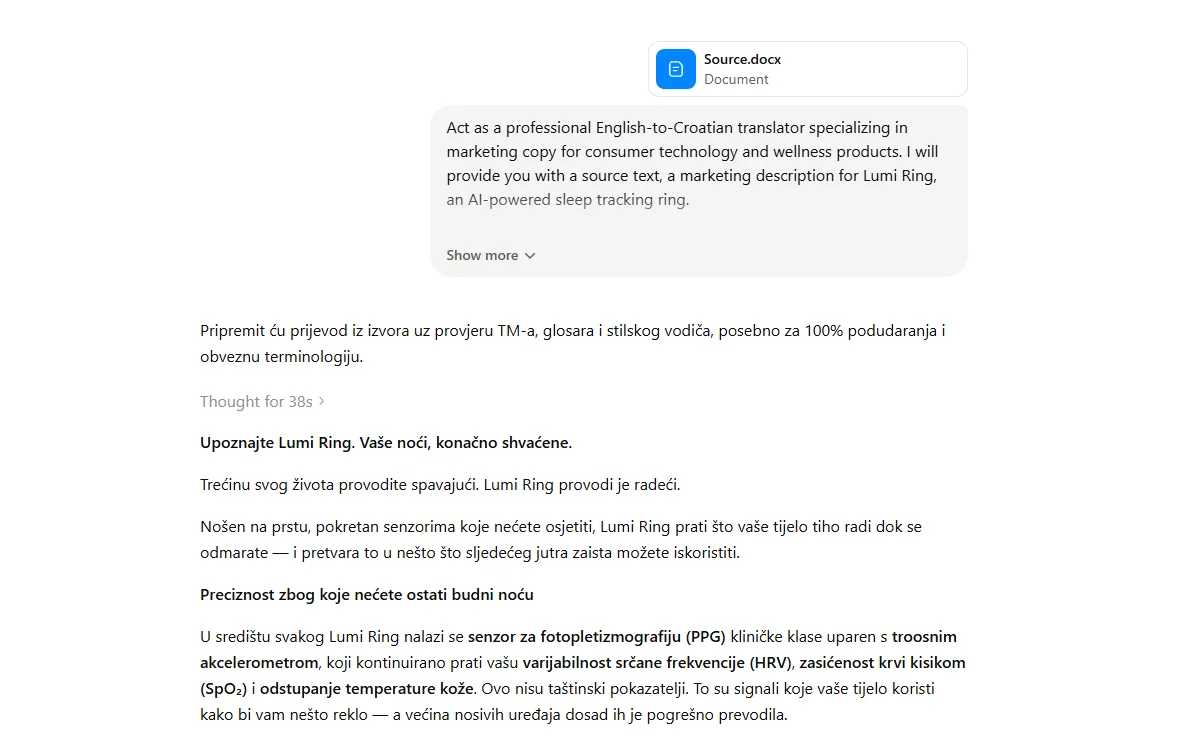
Claude Opus 4.7 🔗
Claude turned out to be the most fluent of the six for the Polish translation. The model applied all TM matches and missed only one 75% entry, rendering "Wskaźnik stresu autonomicznego" instead of the TM's "Autonomiczny wskaźnik stresu". Short source sentences came out less clumsy than in any other model, with fewer word-for-word calques. One headline tripped it up: "Zbudowany na trzech latach Ciebie” for “Built on three years of you” was too literal.
Terminology and style guide were both applied correctly, hence the overall high rating.

In Croatian, the model provided strong results but struggled with style-guide compliance. The key issue was the Croatian diacritics and incorrect SpO2 formatting instead of SpO₂. Overall, the output for this model can be deemed usable for both languages; however, only after careful review.
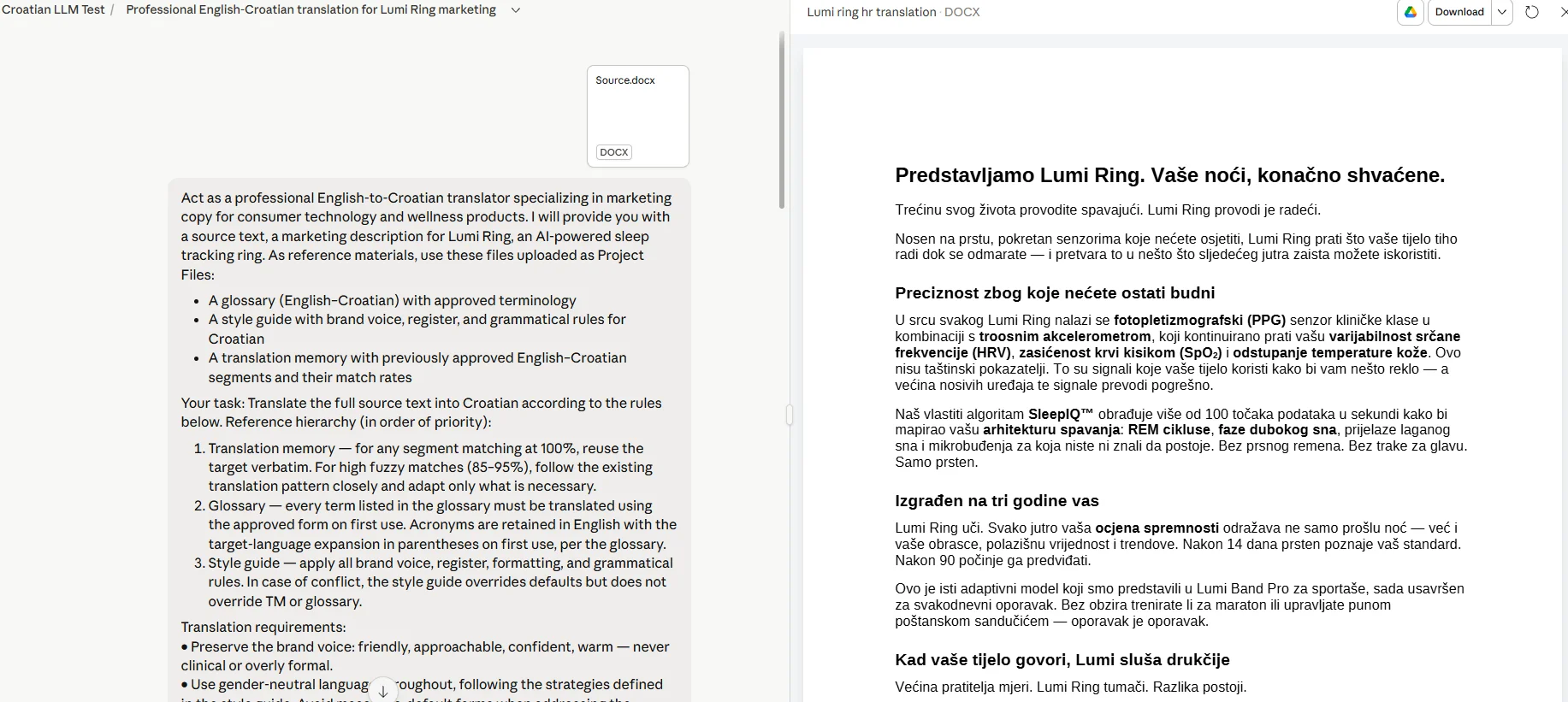
Gemini 3 Thinking 🔗
Since no project feature was available here, the files and instructions were uploaded together with the prompt. In Polish, the model showed a couple of accuracy issues. "Have been interpreting" came out as "interpretowała" – a verb rendered in past tense, where "interpretuje" (present tense) would have been more appropriate in this context. A grammar slip appeared in one string, and the TM also took some hits. The model failed to replicate a few phrases from the memory, missing similar entries to ChatGPT. Terminology and style guide were otherwise applied correctly.
In Croatian, the model ranked high for fluency but ignored the style guide on several occasions. For example, the phrase “fotopletizmografija (PPG) senzor” wasn’t rendered correctly. A more idiomatic option would be “senzor za fotopletizmografiju (PPG)” or “senzor fotopletizmografije (PPG)”. The term “SpO₂” wasn’t formatted as per the style guide, some phrases included agreement problems (e.g., in “Dostupno sada u bojama Midnight, Chalk i Sand.”), and a few technical terms came out with awkward phrasing.
DeepSeek R1 (DeepThink/Expert) 🔗
There is no project feature here either, so files and instructions were uploaded together with the prompt. For both translation tasks, the model took the longest time to think. Croatian translation appeared after approximately 6 minutes, while for other models, the thinking time never exceeded 3 minutes. Before displaying the Polish translation, the model thought for 211 seconds. This time was not spent recklessly, though. Deepseek turns out to be the most thorough on TM entries in both languages.
For example, in Polish, all matches were applied correctly, including the low ones and the tricky entry with "autonomiczny wskaźnik stresu" (“autonomic stress index“) that tripped up most other models.
In Croatian, the model applied the TM, style guide, and glossary with surgical precision, delivering the second-best translation.

It was not all roses, though, and both languages included minor blunders. In Croatian, some phrases were slightly less natural from the marketing perspective. One good example of this issue can be found in “na temelju vaše akumulacije duga spavanja u stvarnom vremenu”. The phrase was translated accurately, but sounds nothing like the approachable technical language prescribed in the style guide. A lighter Croatian marketing version would be “na temelju vašeg stvarnog nakupljanja duga spavanja”.
In Polish, there were minor grammar mistakes, literal phrasing, and a few clumsy constructions. Gender neutrality was missed for "pracowników" (“workers”), but other requirements of the style guide and terminology were applied correctly.
It seems that what DeepSeek gained in precision, it lost in fluency.
Qwen 3.6-Plus 🔗
This model offers a Project feature, so reference files were uploaded as project files. It also took longer to analyze the file, compared to the Western group models. In Polish, the TM compliance was solid with only one low-match entry missed ("Autonomiczny wskaźnik stresu"). The problem was fluency. Clumsy compounds like "mikro-wybudzenia", awkward phrase order in "faza lekkiego snu" for “light sleep transitions”, and constructions like "kontekst do działania" (“Actionable context”) and "stres późnonocny" (“late-night stress “) made the text feel unpolished. Passive voice appeared where it wasn't needed. The model translated accurately, but not as a professional native translator would.
Things didn’t look up for the Croatian translation either. Overall, Qwen provided the weakest output for this language pair. Grammar hiccups, case-related conflict, and missing context were the key issues behind the lowest ranking. One example of issues in this category is the phrase “na temelju vašeg dug spavanja u stvarnom vremenu”, which is not grammatically correct. After “vašeg”, the noun phrase must agree in case, so the correct form would be “vašeg duga spavanja” or, more naturally in this context, “vašeg stvarnog nakupljanja duga spavanja”.
Kimi K2.6 Thinking 🔗
Like DeepSeek, this model spent a lot of time on thinking (nearly 9 minutes), and all instructions plus files had to be fed as a simple prompt because of the missing Projects feature. In the case of the Polish translation, the thinking time was rewarded with probably the most creative translation in the set. It was less literal than ChatGPT or Gemini, with noticeably better flow. On TM, Kimi missed only one low-match entry ("wskaźniki stresu autonomicznego"). Two issues pulled the score down. The first one was the gendered forms for "podróżników" and "pracowników", although the style guide required neutral phrasing. Another one was a fluency glitch in the final two sentences, both of which contained the same word ("już"), a repetition that a quick read-through would have caught. Or one that a professional translator wouldn’t have made at all.
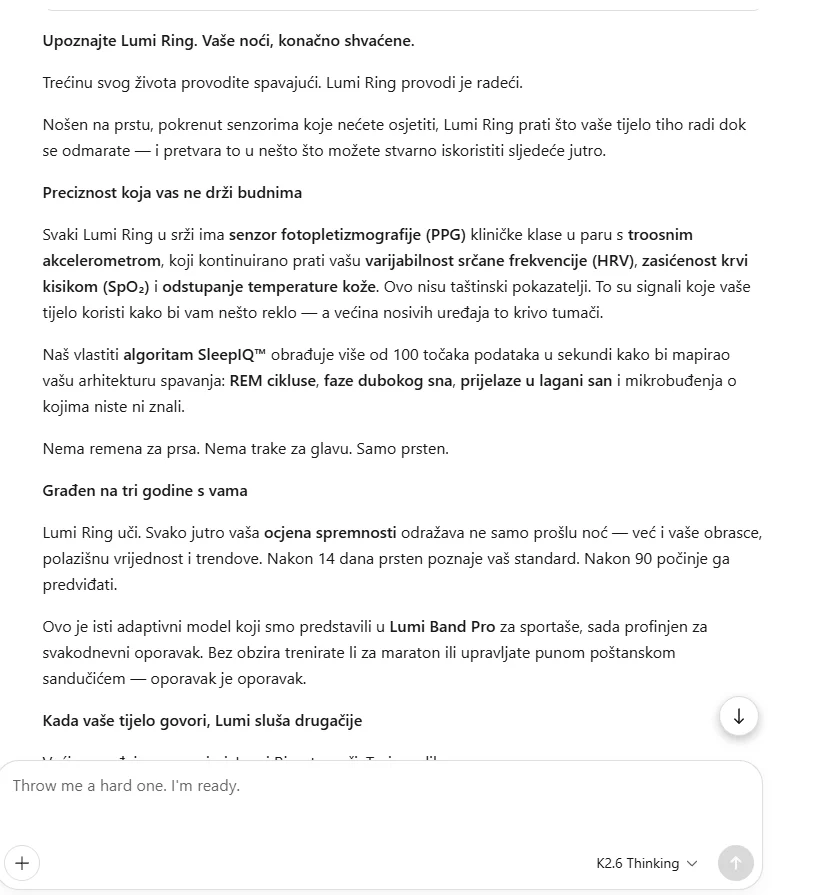
For the Croatian translation, the model generated natural and marketing-friendly text, doing its best to apply all the provided resources. The TM and glossary compliance were strong, but it struggled with fluency. There were linguistic and structural issues, including case/agreement problems and changes to line breaks.
📋 What’s the LLM leaderboard? 🔗
This is how each LLM scored for each indicator and language combination:
| LLMs | Consistency with translation memories | Coherence across paragraphs | Consistency with the style guide | Contextual appropriateness | Accuracy | Fluency | Total Score |
|---|---|---|---|---|---|---|---|
| Claude | 4 | 5 | 5 | 5 | 5 | 4 | 28 |
| Kimi | 4 | 5 | 4 | 5 | 5 | 4 | 27 |
| DeepSeek | 5 | 5 | 4 | 5 | 5 | 3 | 27 |
| Qwen | 4 | 5 | 5 | 5 | 5 | 3 | 27 |
| Gemini | 4 | 5 | 5 | 5 | 4 | 3 | 26 |
| ChatGPT | 3 | 5 | 5 | 5 | 5 | 3 | 26 |
| LLMs | Consistency with translation memories | Coherence across paragraphs | Consistency with the style guide | Contextual appropriateness | Accuracy | Fluency | Total Score |
|---|---|---|---|---|---|---|---|
| ChatGPT | 4 | 4 | 4 | 4 | 5 | 5 | 26 |
| DeepSeek | 4 | 4 | 4 | 4 | 4 | 4 | 24 |
| Claude | 4 | 4 | 3 | 4 | 4 | 4 | 23 |
| Qwen | 4 | 4 | 3 | 3 | 4 | 3 | 21 |
| Gemini | 4 | 4 | 3 | 3 | 3 | 3 | 20 |
| Kimi | 3 | 3 | 3 | 4 | 3 | 4 | 20 |
History repeats itself. battle no. 1 ended with no clear winner, and so does battle no. 2. All tested LLMs turned out to be extremely powerful and capable of rendering correct translations in Polish and Croatian, based on the provided context. No matter the setup (whether it was a project or a simple prompt with all files attached), the models accessed style guides, glossaries, and translation memories, spent some time analyzing the context, followed the prompt accurately, and created content that was not only linguistically correct, but also, in most cases, in line with the brand rules.
ChatGPT was the least accurate when it comes to reusing entries from the Translation Memory, while DeepSeek was the most precise in this aspect, applying all matches, even those below 80%. Glossary and style guide enforcement (excluding the rule on gender neutrality) was handled correctly by most models in both languages.
This time, all tested LLMs were extremely powerful and capable of rendering correct translations in both Polish and Croatian when given the context. Guides, glossaries and TMs were used, and the content created based on them was mostly in line with brand rules
Of course, this doesn't mean that the translations were perfect. While there were no big issues in terms of accuracy, fluency varied, leaving room for improvement. Literal phrases and grammatically awkward constructions appeared in nearly every output to a different extent. Although the texts could have been infused with more creativity and personality, they were mostly on brand and aligned with the provided context.
🆚 East or West: what’s the best? 🔗
When it comes to the Western vs. Eastern divide, our test shows that DeepSeek, Qwen, and Kimi generate results comparable with the frontier models, at least for the languages and content selected for our experiment.
There is no clear winner in this group. The interesting part, however, is that for Polish translation, the Eastern models slightly outperformed ChatGPT and Gemini, while Claude led the overall leaderboard. For Croatian, it was ChatGPT that took the spot no. 1, followed by DeepSeek and Claude.
Simply put, the East retains its strong position thanks to DeepSeek, and the West shines through strong results from ChatGPT (for Croatian) and from Claude (for Polish). These results may, of course, vary depending on the language pairs, content type, and the quality of the provided context.
🏆 And the winner is… 🔗
What does it all mean for your content? Which LLM should you choose for your translations?
There’s no universal solution, but one thing is sure: the future is integrated. No one will spend time and tokens to manually run multiple prompts for multiple language pairs in several LLMs, and with several reference documents attached to the prompt. For the best result, you need a system that lets you easily choose the model that delivers the best result for your language and content type, upload context that stays in the system and is reusable, when necessary, plus provide instruction that can be applied to other projects. That’s exactly what an orchestrated, agentic system offers.
One such solution is Localazy: you upload your glossary, add TM and a style guide, and run pre-translation using their proprietary model, Localazy AI, which has been fine-tuned to provide the best for localization use cases. The same context materials can be used for translation into several languages, so there’s no need to create a separate project per language or copy-paste your prompt in the LLM’s interface several times. Everything is connected, easy to use, and transparent when it comes to token use.
If that sounds too good to be true, have a look at the test I’ve performed recently to find out if Localazy AI can handle the context correctly.
💬 FAQs 🔗
Have Chinese LLMs improved since 2025? 🔗
According to research from OpenRouter and Andreessen Horowitz, Chinese open-source models went from roughly 1.2% of global AI usage in late 2024 to nearly 30% by the end of 2025. Their performance has improved significantly. For example, DeepSeek’s V3.2-Speciale model won gold medals in the International Mathematical Olympiad and the International Olympiad in Informatics.
According to BenchLM.ai, the gap between the Chinese model and the global frontier is shrinking. Number one Chinese LLM is DeepSeek V4 Pro (Max), followed by DeepSeek V4 Pro (High) and Kimi K2.6. CAISI Evaluation assessed that DeepSeek V4’s capabilities lag behind the frontier models by about 8 months. This assessment also confirms that DeepSeek V4 is more cost-efficient than other models of similar capability.
Are Chinese AI models as good as Western models for translation? 🔗
Our tests prove that the top Chinese models (especially DeepSeek) are comparable to the Western models when it comes to translation. With the relevant context and precise instructions, these models are able to generate decent results.
Which LLM is best for localizing a mobile app? 🔗
There’s no one-size-fits-all solution. The results will vary depending on the language. According to the findings of the WMT25 General Machine Translation Shared Task, the best system overall was Gemini 2.5 Pro (it ended up in the top cluster in 14 language pairs). Our experiments from the Translation War no. 1 focused on mobile apps showed that DeepSeek is the top model for localizing mobile apps into Polish, and Claude for Croatian.
The Intento report highlights that it’s the multi-agent workflow that delivers the best results. Bear in mind that top models constantly get new updates, and their results change. What’s the best varies depending on whether you prioritize translation accuracy, brand voice, terminology consistency, creativity, or privacy constraints. Whatever you choose, don’t forget about the human review, as studies show tone, nuance, and cultural fit still need careful oversight.



